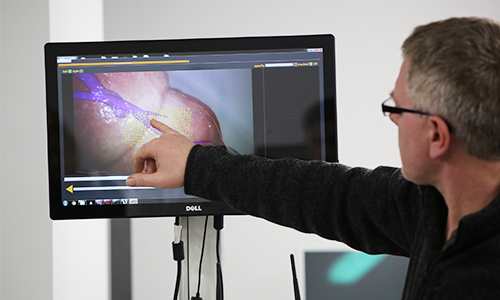
UCL Centre for Medical Image Computing (CMIC) Our aim is to make an impact on key medical challenges facing 21st century society through world-leading research on medical imaging, image analysis, and image-based modelling technologies and applications. YouTube Widget Placeholderhttps://www.youtube.com/watch?v=K6rs1FYqiSY&list=PLQcRhEFbPrx4fb6jiOaaVl... Research Groups We combine expertise from mathematical and computational sciences and medical physics to develop imaging technology for healthcare applications. About CMIC links technical academic staff, researchers, and students with clinical partners. Find out more about the Centre. Contact We're always interested in hearing from potential collaborators or interested others, find out how to get in touch. News Read the latest news from CMIC. Software and Resources Since its launch in 2005, CMIC has generated a wealth of open-source software and resources. CMIC in UCL newsFunnelback feed: https://cms-feed.ucl.ac.uk/s/search.json?collection=drupal-push-news-new...Double click the feed URL above to editRecent CMIC newsFunnelback feed: https://cms-feed.ucl.ac.uk/s/search.json?collection=drupal-engineering-s...Double click the feed URL above to editUpcoming eventsFunnelback feed: https://cms-feed.ucl.ac.uk/s/search.json?collection=drupal-engineering-s...Double click the feed URL above to edit




 Close
Close
